This is about
Code
6 minutes
02 Mar 2021
This is about
Code
6 minutes
02 Mar 2021
The ins and outs of facial recognition


At 14islands we usually like to use our Friday hacks to explore new territory. Sometimes an idea can pan out and turn into a beautiful project. Other times it doesn’t pan out but serves a learning purpose. This post will share some of our experience with the latter.
Facial recognition is something that we always wanted to explore. There are many libraries out there, so we decided to pick one and see how far we could push in a scoped and time-constrained project. The project was nicknamed “Face to Audio.”
What it is
Facial recognition is the act of matching some face models to the given face input to figure out where the coordinates of that face are.
There are different libraries that can perform this task for you. The idea surely has some dark sides to it, but that was faaaar from our intention. 😉 We didn’t intend to save any data or use any kind of artificial intelligence for better results. We just wanted to use our experiment to play some sounds and/or music.
We tried both face-api.js first and then clmtrackr. We sticked to clmtrackr because it had some additional features and provides better performance, according to our tests.
The initial idea
The idea was to generate sounds according to the facial expressions you perform on the webcam.
Add the fact that we had a brilliant trip to Tokyo, and the design just had to be Japanese-based.
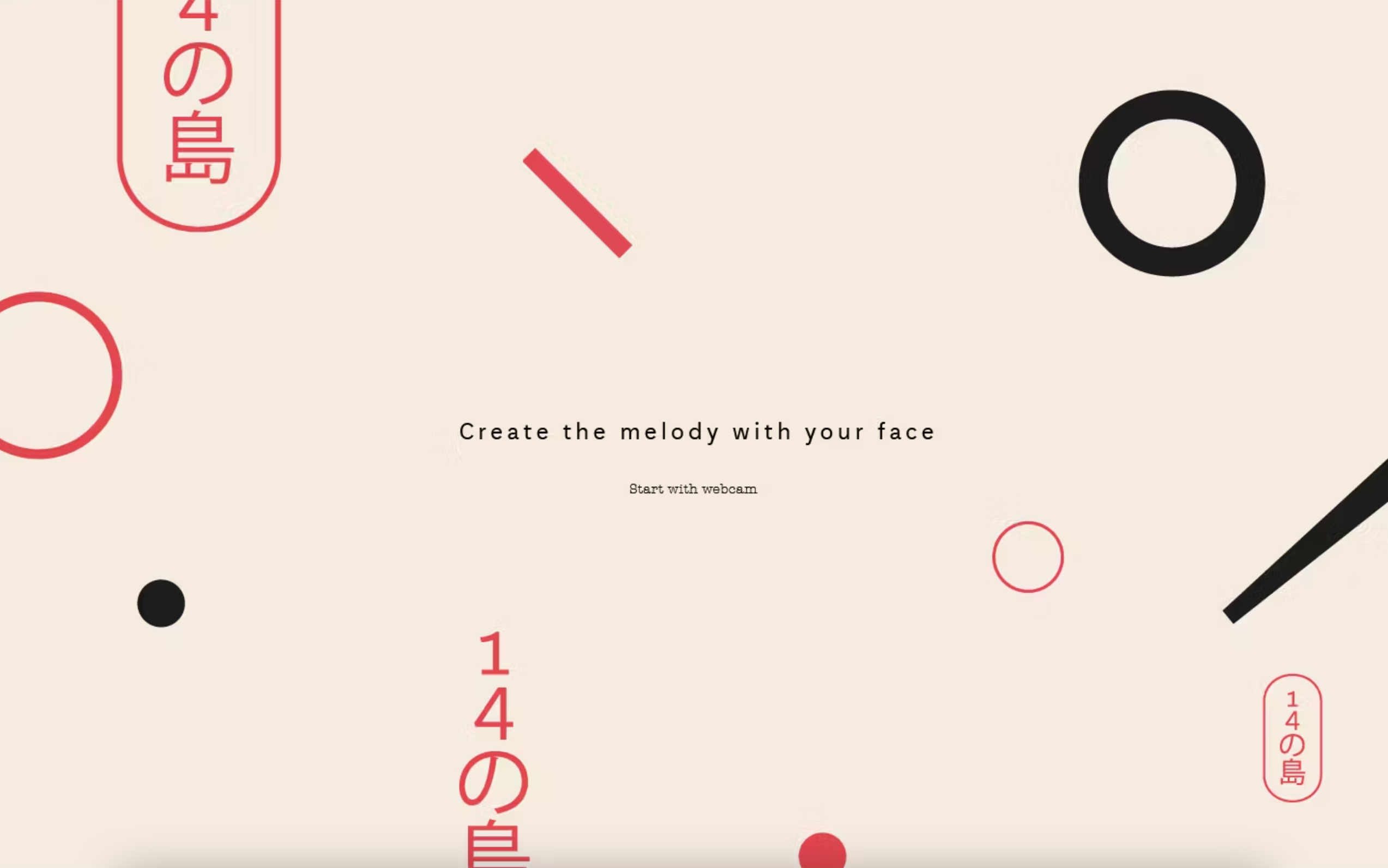
With the design figured out, the next challenge was to find good sound samples for the application. It’s actually really hard to find good sound samples on the web today — do let us know if you know any good sources! Fortunately, with some help from a DJ friend, we got what we needed.
The code logic
The library gives us some important information in every frame loop, and we make that available through our app. In every frame, we calculate, based on facial landmark positions, if the mouth is open or not, the angle of the eyes, and a best guess at the current emotion. Our plan was to trigger a shape that would be displayed randomly across the screen, with a feedback sound, depending on whether the user was angry, sad, surprised, or happy.
We would then save all of this information in a global object, making the data collected available to different components across the app (overlay, sound manager, etc.).
With the library taking care of this logic out of the box, our job was to make sure the sound feedback would happen properly. Say, if you open your mouth, a sound should happen exactly at that moment.

Any millisecond later, and the application would feel sluggish. Our way to address this was to preload all the sounds and make them loop in the background. The sound is always there, but muted. Once it needs to be played, it is unmuted.
Limitations
Bearded guys like me suffer with the expression detection. Many times, with the debugging turned on, I could see that my chin detection wasn’t exactly where it was supposed to be. That made it very difficult to detect certain movements, like opening the mouth.

We ended up dropping the emotion detection idea and displayed shapes based solely on when you open your mouth, tilt your head, or blink an eye. Not good enough, but at least it proved the concept could be improved upon later.
The initial idea got lost after finding these difficulties.
What we would do differently
We realized that in order to achieve our goal, we would need to spend a lot more time and effort on it. That’s when we decided to drop the project, learn from it, and share our findings here.
Our main challenge was the facial detection. Next time, we would probably try a different library or look into improving the detection of this one. Expression emotions like sad, angry, and happy are either really hard to detect — or perhaps my poker face is just too good. Some libraries can be improved if you provide “models” to them, and clmtools should work well for this one. So we can either update the “models” to feed the tool with different faces (like mine) or pick another library that would give better results.
Two other visual aspects that could bring this to the next level are the video from the webcam and how the scene reacts to it.
For the video, we thought about adding some ornaments or a cartoon around it, since we have the boundaries of the face. That would surely make it more funny and engaging to use. The background art could also have been more “random,” and with more time, we could make the logic more complex by making it less predictable.
Another important aspect are the sound effects. Though the sounds are pretty good, the project missed a “generative” twist to it. You should be able to create a sound or perform in a way that would also affect what you hear instead of getting static feedback.
More complexity for sure, but it would also be more impressive. For now, this way just an experiment to see how far we could push, and that is fine — it does what it’s supposed to do 🙂
Last but not least, if we started this again, we would definitely spend less time picking libraries to get an MVP earlier. This could potentially give us time to plan for more features in the long run. In the end, the emotion detection that this library offers is not being used at all, because of some of the difficulties that we faced.
Learnings
Facial recognition is something that we will probably tap into again in the future. Another area that interests us is augmented reality, so don’t be surprised if we end up exploring both together — hopefully with an award winning project instead of just an experiment.

Kudos to the authors for creating these libraries and making them open source. We like to explore and have fun, and we certainly had it here. The main goal of a Friday hackSee also Why Fridays are Hack Days at 14islandsJournal is to always learn something new and enjoy it while doing it. Hopefully, this post serves as inspiration for that process.
Why Fridays are Hack Days at 14islandsJournal is to always learn something new and enjoy it while doing it. Hopefully, this post serves as inspiration for that process.
Check it out: https://face2audio.netlify.app/
Droplets
Droplets
Sign-up to get the latest insight from 14islands. We send a newsletter only once every quarter with inspirational links and creative news. It's short and sweet. You can unsubscribe it at any time.


